
La perdita di un server DHCP all’interno della rete può costituire un single point of failure portando alla paralisi operativa della rete stessa (dato che non esiste più un server che assegna indirizzi agli host). Normalmente si cerca di porre rimedio a questo problema costruendo uno split scope, vale dire suddividendo l’intervallo degl indirizzi da assegnare tra due server, con l’effetto collaterale sgradevole che, se uno dei due server viene a cadere, il numero totale di indirizzi effettivamente disponibili si dimezza, e può non essere più sufficiente.
Da Windows 2012 in poi Microsoft fornisce una forma di HA (High Availabiltiy) per i server DHCP più sofisticata, consentendo di implementare una architettura più vicina ad un failover vero e proprio, in cui se uno dei server viene a mancare l’altro prende il ruolo del server mancante e tiene traccia di tutti gli indirizzi assegnati. Questa architettura in Windows 2012 chiedeva l’utilizzo di uno storage condiviso (una SAN, soluzione costosa); questo requisito viene a cadere con Windows 2012 r2, con il quale la configurazione di un cluster diventa veramente semplice.
Va detto subito che quanto segue vale esclusivamente per IPv4; d’altra parte in IPv6 normalmente la configurazione è stateless ed il DHCP server viene usato soltanto per trasferire le opzioni di ambito. Se le opzioni di ambito sui due server DHCP sono uguali (in sostanza stanno indicando ai client quale DNS e gateway usare, e se devono gestire le stesse reti saranno uguali), la mancanza di uno dei due costituisce un problema relativo, dato che il DHCP server fornisce solo opzioni di configurazione, e non gli indirizzi agli host (che li acquisiscono via SLAAC).
Requisiti
Il failover DHCP si applica solo a Windows 2012 server e versioni successive; solo due server possono essere posti in failover. Windows 2012 R2 è preferibile (per le ragioni dette sopra).
Configurazione
Supponiamo di avere già configurato uno scope DHCP su uno dei nostri server DHCP (questo articolo porta note utili per la configurazione di un server DHCP) . Nel caso in esempio i server hanno indirizzi 10.0.0.252, 10.0.0.248. La rete, una rete di laboratorio. ha indirizzamento 10.0.0.0/24, con opzioni Gateway 10.0.0.1, DNS 10.0.0.252, 10.0.0248.
Creiamo su SRV01l’ambito:
Amb01: 10.0.0.64 – 10.0.0.95
In DHCP Manager, da Scope, facciamo click con il destro, Configure failover. -> Next -> Partner server, Add server, e selezioniamo il server di replica, cliccando poi Next.
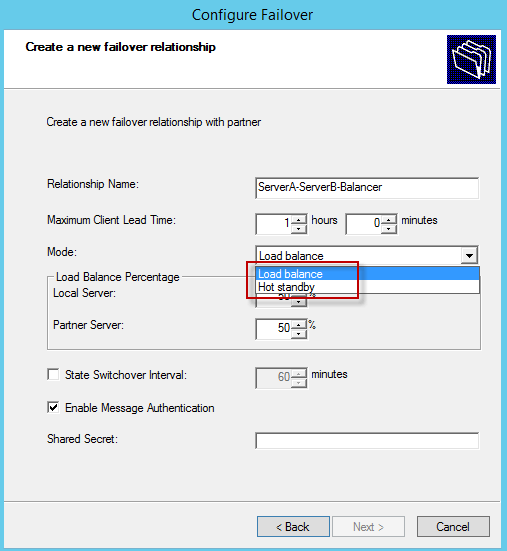
Creiamo una relazione di failover
Maximum cleint lead time: quanto tempo aspetterà il server prima di prendere il controllo dell’intero cluster nel caso il partner fallisca
Mode: load balance: active active, i due server gestiscono entrmbi le richieste distribuendo il carico
Load balance percentage: il server con la percentuale più alta gestisce il carico più elevato
State switchover interval: possimao lasciare il default
Enable message autentication: per scambiare messaggi crittografati tra i server
Una volta configurato il failover, questo è il risultato per come si vede da un client sulla stessa rete, usando dhcploc:
G:\utils>dhcploc 10.0.0.111 14:30:54 OFFER (IP)10.0.0.64 (S)10.0.0.253 *** 14:30:54 OFFER (IP)10.0.0.80 (S)10.0.0.248 *** 14:30:57 OFFER (IP)10.0.0.64 (S)10.0.0.253 *** 14:30:57 OFFER (IP)10.0.0.80 (S)10.0.0.248 ***
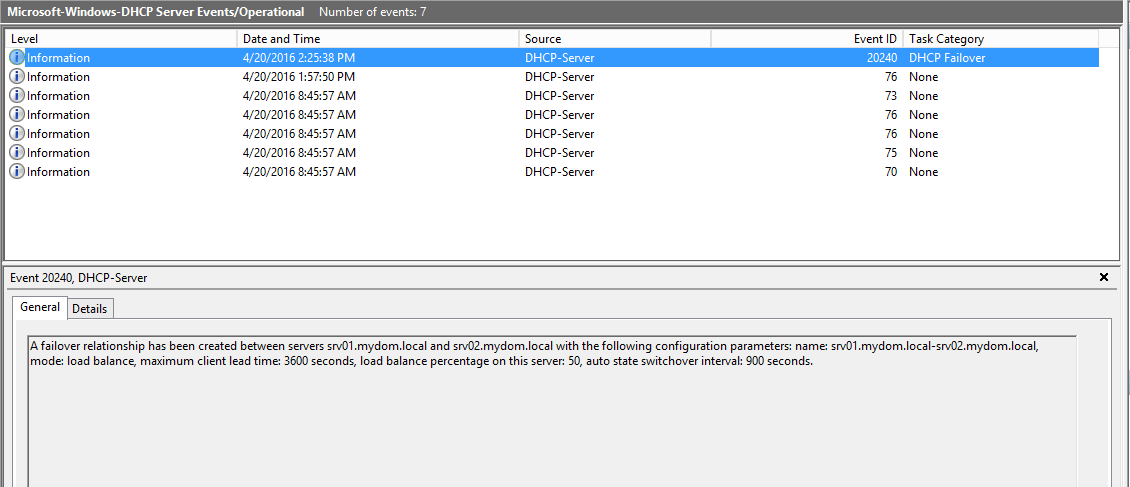
Nel registro degli eventi vedremo un diagnostico di questo genere, che indica la realizzazione del failover:
Vediamo cosa accade in caso di guasto: a questo scopo, la maniera più semplice è quella di disabilitare l’interfaccia di rete di uno dei server (siamo in ambiente di test!). Semplicemente l’altro server continuerà ad offrire indirizzi. Nel registro degli eventi vedremo loggati i messaggi che seguono:
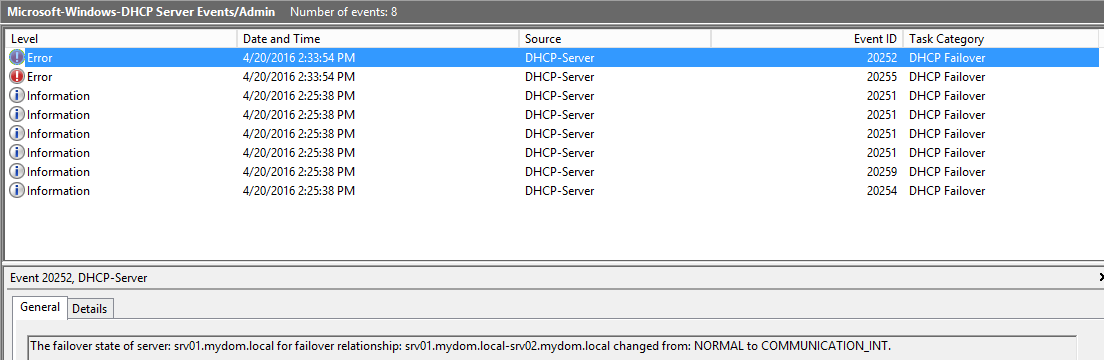
Il messaggio indica la prematura scomparsa del secondo server (che fa sì che la comunicazione tra i due server nel cluster venga a mancare). E’ sufficiente ripristinare l’interfaccia di rete perché il failover torni ad essere attivo, conservando traccia di tutti gli indirizzi assegnati.

Author: admin
bio